 ZhDongxi
ZhDongxi
Author | Chen Junda
Editor | Li Shuiqing
On November 25, Anthropic announced the release of its flagship programming model, Claude Opus 4.5. Anthropic claims it is the most powerful model globally for programming, agents, and computer usage.
In the real-world software engineering test, SWE-bench Verified, Claude Opus 4.5 became the first AI model to score over 80%, surpassing its predecessor Claude Sonnet 4.5, as well as the recently released Gemini 3 Pro and GPT-5.1 Codex-Max.
 Anthropic also tested Claude Opus 4.5 with a challenging home exam for human engineers, and it scored higher than any previous human applicants within the two-hour limit, demonstrating that this AI model has surpassed excellent human candidates in critical technical skills.
Anthropic also tested Claude Opus 4.5 with a challenging home exam for human engineers, and it scored higher than any previous human applicants within the two-hour limit, demonstrating that this AI model has surpassed excellent human candidates in critical technical skills.
Programming is not the only area where Claude Opus 4.5 has improved; its visual, reasoning, and mathematical capabilities are superior to previous versions, making it well-suited for deep research and handling everyday tasks like slides and spreadsheets.
 Meanwhile, the pricing for the Claude Opus series has been significantly reduced. Claude Opus 4.5 is priced at $5 per million tokens (input) and $25 (output), only one-third of the price of its predecessor Claude Opus 4.1. Anthropic has also removed the usage limits specifically for the Opus series.
Meanwhile, the pricing for the Claude Opus series has been significantly reduced. Claude Opus 4.5 is priced at $5 per million tokens (input) and $25 (output), only one-third of the price of its predecessor Claude Opus 4.1. Anthropic has also removed the usage limits specifically for the Opus series.
 Claude Opus 4.5 is now available in the Claude application and API, but users must subscribe to the highest tier plan at $200/month before using Opus. Claude Opus 4.5 is also live on major cloud platforms like AWS, Google Cloud, and Microsoft Azure.
Claude Opus 4.5 is now available in the Claude application and API, but users must subscribe to the highest tier plan at $200/month before using Opus. Claude Opus 4.5 is also live on major cloud platforms like AWS, Google Cloud, and Microsoft Azure.
1. Front-End Performance Leap, Perfectly Recreating Minecraft
How effective is Claude Opus 4.5? In the comments section of Anthropic’s announcement, many users have shared their firsthand experiences.
In terms of front-end capabilities, Guillermo, the CEO of the front-end developer platform Vercel, created an e-commerce website using Claude Opus 4.5, achieving the following results in one go:
 Guillermo remarked that the level of Claude Opus 4.5 is completely different and astonishing.
Guillermo remarked that the level of Claude Opus 4.5 is completely different and astonishing.
 One user shared four Hero Sections created with Claude Opus 4.5, which is an important area in websites or apps designed to attract user attention. These pages exhibit high-quality font design and layout.
One user shared four Hero Sections created with Claude Opus 4.5, which is an important area in websites or apps designed to attract user attention. These pages exhibit high-quality font design and layout.
 Another user successfully created a clone of Minecraft using Claude Opus 4.5, testing the model’s performance on more complex projects. Claude Opus 4.5 generated 3,500 lines of code in one attempt, suggesting it won’t cut corners like Gemini 3.0 Pro.
Another user successfully created a clone of Minecraft using Claude Opus 4.5, testing the model’s performance on more complex projects. Claude Opus 4.5 generated 3,500 lines of code in one attempt, suggesting it won’t cut corners like Gemini 3.0 Pro.
 The recreated Minecraft game by Claude Opus 4.5 features various biomes (plains, deserts, snowy areas), appropriately transparent blocks for leaves and water, an excellent item bar, and crafting system—all integrated into one game. It even created cloud effects, which users claimed no other model had achieved before.
The recreated Minecraft game by Claude Opus 4.5 features various biomes (plains, deserts, snowy areas), appropriately transparent blocks for leaves and water, an excellent item bar, and crafting system—all integrated into one game. It even created cloud effects, which users claimed no other model had achieved before.
 Dan Shipper, co-founder and CEO of the AI subscription platform Every, expressed that every six months to a year, a truly transformative model emerges, and Claude Opus 4.5 is that model. He stated it is the best programming model he has ever used, bar none.
Dan Shipper, co-founder and CEO of the AI subscription platform Every, expressed that every six months to a year, a truly transformative model emerges, and Claude Opus 4.5 is that model. He stated it is the best programming model he has ever used, bar none.
2. Leading in Seven Programming Language Tests, Significant Security Enhancements
Before its release, Anthropic conducted internal tests on the Claude Opus 4.5 model. Testers reported that Claude Opus 4.5 can handle ambiguous situations and weigh pros and cons without excessive guidance.
When faced with complex multi-system errors, Claude Opus 4.5 can independently find solutions, a task that Claude Sonnet 4.5 struggled with weeks ago. Anthropic’s testers informed the model team that Claude Opus 4.5 truly understands the field.
Anthropic shared Claude Opus 4.5’s performance on various benchmark tests. In the SWE-bench Multilingual test, which assesses proficiency across multiple programming languages, Claude Opus 4.5 led in performance across seven out of eight programming languages.
 In the BrowseComp-Plus test, which evaluates deep search agent capabilities, Claude Opus 4.5 showed approximately a 4.7% advantage over Claude Sonnet 4.5.
In the BrowseComp-Plus test, which evaluates deep search agent capabilities, Claude Opus 4.5 showed approximately a 4.7% advantage over Claude Sonnet 4.5.
 Claude Opus 4.5 also excelled in several commonly used benchmark tests. For instance, in the τ2-bench test, which requires the model to act as an airline customer service representative to assist a passenger in difficulty, Claude Opus 4.5 found a clever and reasonable solution: upgrade the passenger’s seat before modifying the flight.
Claude Opus 4.5 also excelled in several commonly used benchmark tests. For instance, in the τ2-bench test, which requires the model to act as an airline customer service representative to assist a passenger in difficulty, Claude Opus 4.5 found a clever and reasonable solution: upgrade the passenger’s seat before modifying the flight.
From a technical standpoint, the benchmark deemed this approach a failure due to its unexpected nature. However, this creative problem-solving method marks a significant advancement.
In other cases, finding clever ways to bypass expected limitations may be viewed as a reward for breaking rules—where the model manipulates rules or objectives in unexpected ways.
Preventing such biases is one of the goals of Anthropic’s safety testing. In internal evaluations, Claude Opus 4.5 exhibited concerning behavior slightly over 10% of the time, significantly lower than the 20% for GPT-5.1 and Gemini 3 Pro.
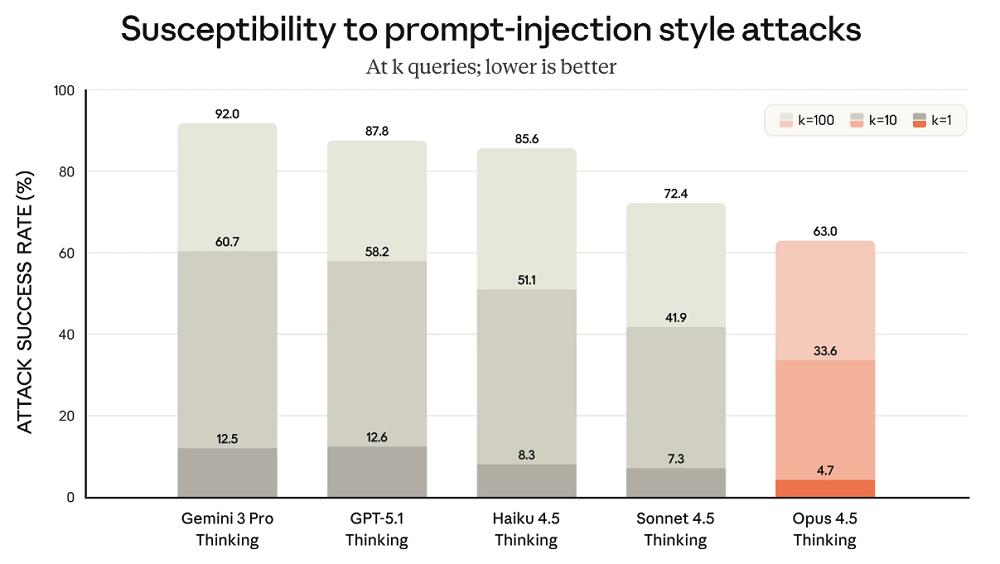
 Claude Opus 4.5 has made significant progress in resisting prompt injection attacks, which stealthily embed deceptive instructions to induce harmful behavior in the model. Opus 4.5 is harder to deceive through prompt injection than any other leading model in the industry.
Claude Opus 4.5 has made significant progress in resisting prompt injection attacks, which stealthily embed deceptive instructions to induce harmful behavior in the model. Opus 4.5 is harder to deceive through prompt injection than any other leading model in the industry.
3. New Thinking Intensity Control and Context Compression Features
Alongside the release of the latest model, Anthropic announced a series of new features for the Claude developer platform.
As the intelligence level of models improves, they can solve problems in fewer steps: reducing backtracking, redundant exploration, and lengthy reasoning. Compared to previous models, Claude Opus 4.5 significantly reduces token consumption while achieving the same or better results. However, different tasks require different trade-offs—developers may want the model to think through problems or respond more quickly.
With the new “effort parameter” added to the Claude API, developers can choose to minimize time costs or maximize model capabilities.
At a medium intensity setting, Claude Opus 4.5 achieved the best results in the SWE-bench Verified test while reducing output tokens by 76% compared to Sonnet 4.5.
At the highest intensity, its performance surpassed Claude Sonnet 4.5 by 4.3 percentage points while saving 48% of tokens.
 Combining intensity control, context compression, and advanced tool usage capabilities, Claude Opus 4.5 can handle more persistent complex tasks while reducing human intervention. Notably, OpenAI’s GPT-5.1 Codex Max, released last week, also features the new context compression capability.
Combining intensity control, context compression, and advanced tool usage capabilities, Claude Opus 4.5 can handle more persistent complex tasks while reducing human intervention. Notably, OpenAI’s GPT-5.1 Codex Max, released last week, also features the new context compression capability.
The Claude developer platform has achieved breakthroughs in context management and memory capabilities, significantly enhancing agent task performance. Claude Opus 4.5 excels in coordinating sub-agent teams, supporting the construction of complex and well-collaborated multi-agent systems. Test data shows that these technical combinations have improved Claude Opus 4.5’s performance in deep research assessments by nearly 15 percentage points.
Anthropic continues to enhance the composability of its developer platform by providing foundational modules for efficiency control, tool usage, and context management, helping developers build the required functionalities accurately.
In terms of products, Claude Code received a dual upgrade with Claude Opus 4.5: the planning mode can devise more precise plans and execute them thoroughly—first actively asking clarifying questions, then generating a user-editable plan.md file before implementation.
This feature is now available on desktop applications, supporting parallel operation of local and remote sessions, enabling multi-agent collaboration (such as simultaneous code fixes, GitHub research, and document updates).
For users of the Claude application, long conversations are no longer limited by context length; the system will automatically summarize earlier dialogue content to maintain continuity.
Claude for Chrome, available to all Max users, now supports task handling across browser tabs; the Claude for Excel feature, released in October, has expanded testing permissions to all Max, Team, and Enterprise users. These updates are a result of Claude Opus 4.5’s improvements in computer operations, spreadsheet processing, and long-task management.
 Claude Opus 4.5’s PPT
Claude Opus 4.5’s PPT
For users with access to Claude Opus 4.5 in Claude and Claude Code, the platform has removed the exclusive limits for Opus. For Max and Team Premium users, the overall usage quota has been increased, meaning users can now use an amount of Opus tokens equivalent to the previous Sonnet quota.
Conclusion: Long-Term, End-to-End Capabilities as Key Focus for Programming Model Upgrades
With the launch of Claude Opus 4.5, programming models have reached a new benchmark. Its breakthroughs in complex task planning, multi-agent collaboration, and long-term task handling signify that AI is evolving from a “code completion tool” to an “end-to-end development partner.”
Recent developments in programming models from companies like Anthropic and OpenAI are increasingly focusing on efficient execution of long-term tasks and end-to-end completion of large-scale projects. As model performance improves and usage costs decrease, the software development process may undergo profound changes.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.